Context engineering cut Claude Code tokens 3x — lessons from Insforge (Skills + CLI)
This week a fairly striking number went around on X: a single context-engineering change pulled Claude Code's token usage down 3x. The same task — building a complete backend with Claude Code — but two ways of connecting the backend produced wildly different results:
Supabase (via MCP): 10.4M tokens · 10 errors · $9.21
Insforge (Skills + CLI): 3.7M tokens · 0 errors · $2.81
≈ 2.8x fewer tokens, 0 errors, ~3.3x cheaper. The interesting question isn't "is Insforge any good," but: why does merely changing how you feed context to the agent save this much?
What is Insforge
Insforge is an "agent-native" backend-as-a-service (a Y Combinator company) — essentially a Supabase competitor, but designed for an AI coding agent to operate it end-to-end: database, auth, storage, edge functions, model gateway, hosting. The core difference: instead of having the agent call through a pile of MCP tools, Insforge lets the agent operate the backend via CLI + Skills.
That's also the heart of this post — not because of the product, but because the mechanism behind it applies to any agent setup.
Why MCP "burns" tokens
MCP (Model Context Protocol) is the popular way today to connect an agent to external services. But when used for a full backend, it has a few quiet token sinks:
- Tool definitions take up the context window from the start. Each tool is a schema; attaching an MCP server with many tools stuffs a whole pile of descriptions into the context before the agent does anything.
- Return payloads balloon. A single tool call can return 10K+ tokens. The agent reads it, then re-reads it on the next turn, over and over.
- The agent has to "discover" constantly. Schema, RLS, table relationships, runtime state... aren't available in machine-readable form up front, so the agent has to query around blindly and verify over many rounds.
- Wrong guesses → errors → repeat. Every error-fixing round means another full read of the context. That's why the "errors" column in the benchmark moves in lockstep with the "tokens" column.
In short: most of the tokens aren't spent doing, they're spent finding the way.
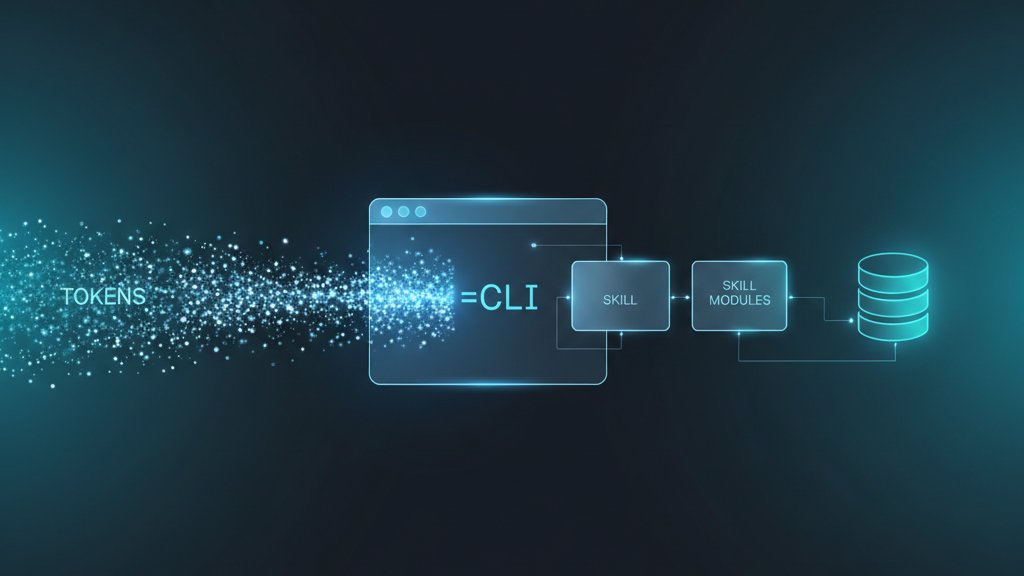
How Insforge "context-engineers" it
The change isn't in the model, but in how context is packaged and put up front:
- Skills — pre-packaged, commonly used workflows and CLI patterns. The agent doesn't waste tokens discovering which tools exist and how to call them; it already has the "recipe."
- CLI — the agent runs deterministic commands instead of "chatty" MCP round-trips. CLI output is compact, stable, and easy to verify.
- Progressive disclosure + semantic layer — surface the relevant schema, RLS, and relationships up front, exactly the part needed, instead of making the agent dig for it.
The result is the agent spends less time "discovering" and more time "executing" — cutting tokens and raising accuracy at the same time. The 0-errors column isn't a coincidence.
Read the numbers with a clear head
A few notes so the marketing doesn't sweep you away:
- This is Insforge's own benchmark, amplified through a promo-heavy account, right as they ran their "Launch Week." Treat it as an illustration of the mechanism, not independent data.
- It's a single task; "3x" is the prettiest framing (the real number ≈ 2.8x).
- The comparison is really Supabase-via-MCP vs Insforge-via-Skills/CLI — i.e. part of what's being compared is the integration method, not the backend alone.
Worth noting: Supabase has counterattacked with its own "Agent Skills" (blog). Meaning the "Skills + CLI beats plain MCP" trend for saving tokens isn't anyone's monopoly — it's a shared direction that Anthropic itself is also pushing.
The usable takeaway
Brand aside, the general lesson is:
To cut tokens for a coding agent, don't pile on more MCP tools. Give the agent structured, up-front, machine-readable context + Skills that pre-package CLI patterns.
That's what "context engineering" actually is — and it's a far bigger token lever than switching to a new model or fine-tuning the prompt. Prompt engineering is syntax; context engineering is infrastructure. And infrastructure always beats syntax.
Sources: