Context engineering giảm token Claude Code 3x — bài học từ Insforge (Skills + CLI)
Tuần này trên X lan truyền một con số khá giật: chỉ một thay đổi về context engineering đã kéo token của Claude Code xuống 3 lần. Cùng một bài toán — dựng một backend hoàn chỉnh bằng Claude Code — nhưng hai cách kết nối backend cho ra kết quả lệch hẳn:
Supabase (qua MCP): 10.4M tokens · 10 lỗi · $9.21
Insforge (Skills + CLI): 3.7M tokens · 0 lỗi · $2.81
≈ 2.8x ít token hơn, 0 lỗi, rẻ hơn ~3.3 lần. Câu hỏi thú vị không phải "Insforge có hay không", mà là: tại sao chỉ đổi cách đưa context cho agent lại tiết kiệm nhiều đến vậy?
Insforge là gì
Insforge là một backend-as-a-service "agent-native" (công ty trong Y Combinator) — về bản chất là một đối thủ của Supabase, nhưng thiết kế để AI coding agent vận hành end-to-end: database, auth, storage, edge functions, model gateway, hosting. Điểm khác biệt cốt lõi: thay vì để agent gọi qua một loạt MCP tool, Insforge cho agent thao tác backend bằng CLI + Skills.
Đây cũng là tâm điểm của bài viết — không phải vì sản phẩm, mà vì cơ chế đằng sau nó là thứ áp dụng được cho bất kỳ setup agent nào.
Vì sao MCP "đốt" token
MCP (Model Context Protocol) là cách phổ biến hiện nay để nối agent với dịch vụ ngoài. Nhưng khi dùng cho một backend đầy đủ, nó có vài chỗ ngốn token âm thầm:
- Định nghĩa tool chiếm chỗ context window ngay từ đầu. Mỗi tool là một schema; gắn một MCP server nhiều tool là nhồi cả đống mô tả vào context trước cả khi agent làm gì.
- Payload trả về phình to. Một lần gọi tool có thể trả về 10K+ token. Agent đọc, rồi đọc lại ở lượt sau, lặp đi lặp lại.
- Agent phải "khám phá" liên tục. Schema, RLS, quan hệ bảng, trạng thái runtime... không có sẵn ở dạng máy đọc được, nên agent phải truy vấn dò dẫm rồi verify nhiều vòng.
- Dò sai → sinh lỗi → lặp lại. Mỗi vòng sửa lỗi là thêm một lượt đọc toàn bộ context. Đây là lý do cột "lỗi" trong benchmark đi cùng cột "token".
Nói ngắn gọn: phần lớn token không tiêu cho việc làm, mà cho việc dò đường.
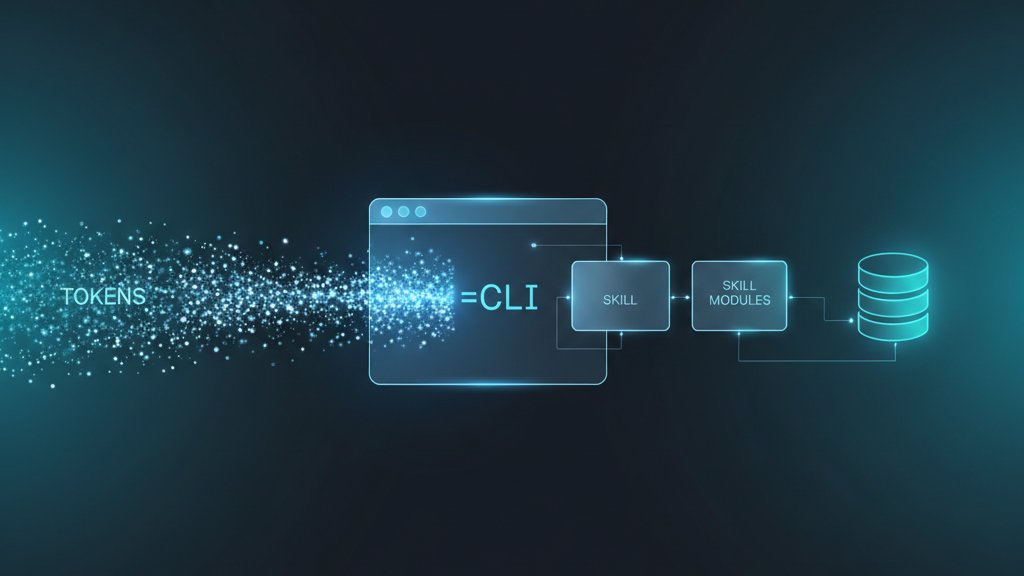
Cách Insforge "context-engineer"
Thay đổi không nằm ở model, mà ở cách context được đóng gói và đưa lên trước:
- Skills — đóng gói sẵn các workflow và pattern CLI thường dùng. Agent không phải tốn token đi khám phá xem có những tool nào, gọi ra sao; nó đã có "công thức".
- CLI — agent chạy lệnh xác định thay cho các round-trip MCP "lắm lời". Lệnh CLI có output gọn, ổn định, dễ kiểm chứng.
- Progressive disclosure + semantic layer — đưa thẳng schema, RLS, quan hệ liên quan lên trước, đúng phần cần, thay vì để agent tự đào.
Kết quả là agent dành ít thời gian "khám phá" và nhiều thời gian "thực thi" hơn — vừa giảm token vừa tăng độ chính xác cùng lúc. Cột 0 lỗi không phải ngẫu nhiên.
Đọc con số một cách tỉnh táo
Vài lưu ý để không bị marketing cuốn đi:
- Đây là benchmark của chính Insforge, được khuếch đại qua một tài khoản chuyên promo, đúng dịp họ chạy "Launch Week". Hãy xem là minh hoạ cơ chế, không phải số liệu độc lập.
- Đó là một bài toán đơn lẻ; "3x" là cách đóng khung đẹp nhất (số thật ≈ 2.8x).
- Phép so sánh thực chất là Supabase-qua-MCP vs Insforge-qua-Skills/CLI — tức một phần đang so cách tích hợp, không thuần backend.
Điểm đáng chú ý: Supabase đã phản công bằng "Agent Skills" của riêng họ (blog). Nghĩa là xu hướng "Skills + CLI thắng MCP thuần" cho việc tiết kiệm token không phải độc quyền của ai — nó là hướng đi chung mà cả Anthropic cũng đang đẩy.
Takeaway dùng được
Bỏ qua chuyện thương hiệu, bài học khái quát là:
Muốn giảm token cho coding agent, đừng nhồi thêm MCP tool. Hãy cho agent context có cấu trúc, đưa lên trước, máy đọc được + Skills đóng gói sẵn pattern CLI.
Đó mới đúng là "context engineering" — và nó là đòn bẩy token lớn hơn nhiều so với việc đổi sang model mới hay tinh chỉnh prompt. Prompt engineering là cú pháp; context engineering là hạ tầng. Và hạ tầng luôn thắng cú pháp.
Nguồn: