Context Engineering — Cấu trúc file và Dynamic Loading cho AI Assistant
Mở đầu
Phần lớn người dùng AI vẫn nghĩ bí quyết để có output tốt hơn là viết prompt khéo hơn. Họ thêm "act as a senior expert", "think step by step", tweak từng từ, chạy đi chạy lại. Kết quả gần như không đổi.
Lý do: prompt engineering là cú pháp, context engineering là hạ tầng. Hạ tầng luôn thắng cú pháp.
Bài này tóm tắt cách tổ chức context cho AI assistant theo kiến trúc 4 file + dynamic loading rules. Mục tiêu: thay vì nhồi mọi thứ vào một CLAUDE.md duy nhất rồi mong model "đọc kỹ", ta chia nhỏ và load đúng phần khi cần — giống cách một thư viện mã nguồn được tổ chức theo module thay vì 1 file dài 5000 dòng.
Vấn đề: prompt-only đã hết dư địa
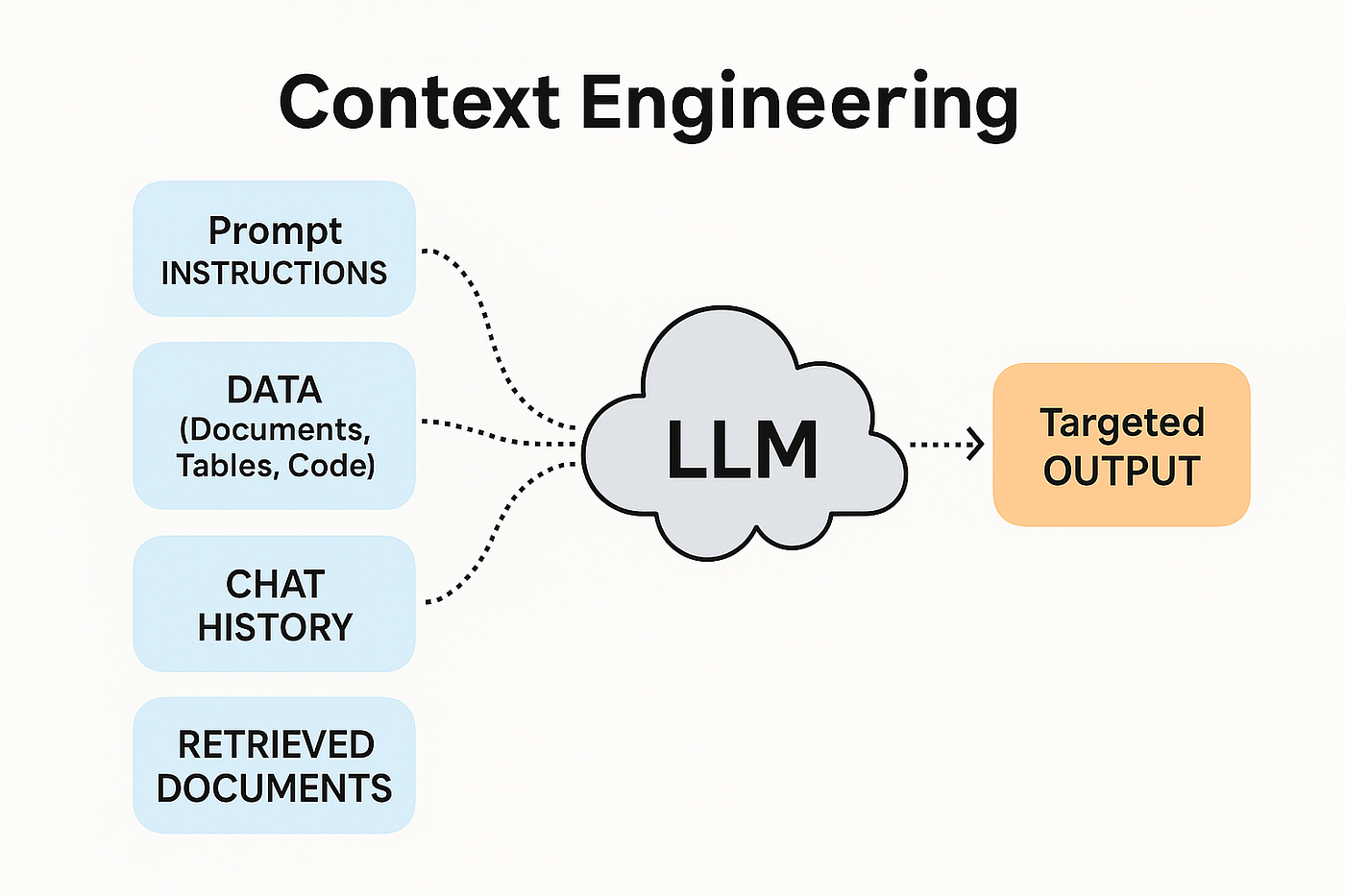
Khi bạn gõ một câu vào Claude (hoặc bất kỳ LLM nào), model không chỉ thấy câu của bạn. Nó thấy toàn bộ context window: system prompt, lịch sử hội thoại, file đính kèm, definitions của tool, và prompt mới nhất. Tất cả xử lý cùng nhau.
Prompt là một nguyên liệu. Context là cả căn bếp.
Đa số người dùng obsess về nguyên liệu mà bỏ qua căn bếp. Họ viết một prompt đẹp rồi paste vào cuộc trò chuyện trống không có context gì. Output ra generic vì model không có gì để cá nhân hóa: nó không biết công việc của bạn, đối tượng của bạn, tiêu chuẩn của bạn, hay những quyết định trước đó. Một model "mù" mặc định trả về output an toàn, trung bình, nhạt.
Context engineering giải quyết bằng cách "cho model con mắt".
Khái niệm: 3 lớp context
Mỗi tương tác AI có 3 lớp context. Đa số người mới chỉ dùng 1.
Lớp 1 — Immediate context. Là prompt bạn gõ ngay lúc đó. Câu hỏi, instruction, format mong muốn. 99% người dừng ở đây.
Lớp 2 — Session context. Là mọi thứ model thấy trong một cuộc trò chuyện: file upload, lịch sử messages, system instructions. Hầu hết người dùng dùng phần nào nhưng không thiết kế chủ ý.
Lớp 3 — Persistent context. Là kiến thức tồn tại qua nhiều session. Memory systems, context files, knowledge base, preferences đã save. Gần như không ai dùng đúng — và đây là nơi đòn bẩy lớn nhất.
Bài này tập trung vào lớp 3 — cụ thể là cách thiết kế persistent context thành cấu trúc file có thể maintain.
Kiến trúc 4 file
Thay vì nhồi mọi thứ vào một CLAUDE.md (hoặc system prompt) duy nhất, tách thành 4 file độc lập. Mỗi file dưới ~2,000 từ để vừa context window và để dễ update.
identity.md — "Tôi là ai"
Nội dung: - Vai trò của AI assistant: là code reviewer, content writer, data analyst, hay general assistant? - Phạm vi: được phép làm gì, không được phép làm gì - Communication style: ngôn ngữ chính, ngôn ngữ phụ, tone (formal / informal), độ dài câu trả lời mặc định - Format ưa thích: markdown, plain text, có emoji hay không, có dùng heading hay không - Hard constraints: không bao giờ làm X, luôn luôn làm Y khi gặp Z
Đây là "onboarding document" cho AI. Nếu bạn thay người mới trong team, bạn sẽ giải thích những gì? Viết đúng những thứ đó.
audience.md — "Tôi phục vụ ai"
Nội dung: - User chính: ai, background, expertise level - Pain points: họ ghét gì (verbose AI, generic answers, mention thứ họ đã biết...) - Preferences: thích bullet hay paragraph, thích citation hay không, thích Vietnamese hay English - Anti-patterns: những kiểu trả lời từng làm họ frustrated trước đây - Decision authority: user có quyền quyết định gì, AI nên hỏi trước khi làm gì
File này đảm bảo output targeted, không generic. Một câu trả lời "đúng" với senior dev khác hoàn toàn câu trả lời "đúng" với marketing manager — dù prompt giống nhau.
standards.md — "Chất lượng tốt là gì"
Nội dung: - Coding principles: Read Before You Write, Convention Beats Novelty, Surgical Changes (rule cụ thể, không slogan) - Quality criteria: khi nào output được coi là "đủ tốt" để gửi - Anti-patterns trong domain: ví dụ đoạn code bị reject, ví dụ paragraph bị reject - Examples of excellent work: 1-2 mẫu output chuẩn để model calibrate - Hard rules: không bao giờ commit secret, không bao giờ disable test, không bao giờ refactor adjacent code
Đây là "quality control system". Mỗi rule phải answer: rule này ngăn được cái sai cụ thể nào? Rule không trace được về 1 failure thực thì là noise, cắt bỏ.
project.md — "Đang làm gì hiện tại"
Nội dung (file này dynamic, update thường xuyên): - Active projects: liệt kê + 1 dòng mô tả mỗi project - Recent decisions (rolling, last 30 ngày): "ngày X chọn approach Y vì lý do Z" - Open questions: những thứ chưa quyết, đang chờ thông tin - Deadlines / milestones: thời điểm quan trọng sắp tới - Tools / capabilities available: SSH alias, API key location, cron jobs đang chạy, MCP servers connected - Where things live: folder layout, deployment URL, log location
Đây là lớp dynamic — đổi mỗi tuần. Mục đích: AI không cần hỏi "project hiện tại đang ở đâu" mỗi session.
Dynamic Loading Rules — không load tất cả mỗi session
Đây là phần quan trọng nhất, và là phần đa số setup bỏ qua.
Vấn đề: Load toàn bộ knowledge base vào mỗi conversation là lãng phí token VÀ làm giảm performance. Khi context window bị nhồi với thông tin không liên quan, attention của model bị dilute. Nó cố dùng mọi thứ và kết cục không dùng tốt cái nào.
Giải pháp: Pre-define rule load tương ứng với từng task type.
Ví dụ rule load:
TASK TYPE | LOAD
-----------------------------|------------------------
Mọi session | identity.md, audience.md
Coding / system design | + standards.md
Touching specific project | + project.md
Content summarization | (chỉ identity + audience)
Quick Q&A (math, lookup) | (không load thêm gì)
Strategic planning | + project.md + standards.md
Research | + project.md
Rule này được viết trong file root (CLAUDE.md hoặc system prompt) như một index. Khi nhận task, AI tự phân loại task, đọc rule, rồi dùng tool (Read file) để load file phù hợp.
Kết quả: - Task summarize nội dung: ~70 dòng context (identity + audience) - Task code: ~120 dòng (thêm standards) - Task touching project: ~170 dòng (thêm project)
So với monolithic 280 dòng load mỗi turn, tiết kiệm 40-75% token và quan trọng hơn: attention của model không bị dilute với thông tin không liên quan.
Cấu trúc thư mục cụ thể
your-project/
├── CLAUDE.md ← root, ~20 dòng (auto-load)
└── .claude-context/
├── identity.md ← ~30-50 dòng
├── audience.md ← ~20-30 dòng
├── standards.md ← ~50-70 dòng
└── project.md ← ~50-70 dòng (dynamic)
CLAUDE.md root chỉ chứa 3 thứ:
- Identity 1 đoạn ngắn (5 dòng) — đủ để biết bot là ai, dù chưa load file nào
- Loading rules — bảng map task type → file cần load
- File index — list 4 file con + 1 dòng mô tả mỗi file
Ví dụ root content:
You are <role>. Working dir: /your-project/.
Context files at .claude-context/:
- identity.md: who I am
- audience.md: who I serve
- standards.md: code/communication rules
- project.md: active work + tools
Loading rules (read these files at task start when matching):
- ALWAYS: identity.md, audience.md (small, ~50 lines combined)
- IF coding/system design: + standards.md
- IF touching active project: + project.md
- IF just summarizing content: nothing extra
- IF quick Q&A: nothing extra
20 dòng đó là toàn bộ những gì auto-load mỗi session. Mọi context khác là on-demand.
Workflow của AI khi nhận task
- Đọc CLAUDE.md root (auto, không tốn tool call)
- Phân loại task theo loading rule
- Load file phù hợp qua Read tool (1 tool call/file)
- Chạy task với context vừa đủ
Ví dụ cụ thể:
- User: "Tóm tắt bài blog này → 5 bullet"
- AI phân loại: content summarization → chỉ identity + audience
- AI Read identity.md → thấy "trả lời tiếng Việt, terse, không fluff"
- AI Read audience.md → thấy "user là dev senior, không cần explain basic term"
- AI tóm tắt với context vừa đủ — không bị nhiễu bởi standards.md (rule code) hay project.md (project list)
So sánh: monolithic vs split
| Tiêu chí | Monolithic CLAUDE.md | 4-file + dynamic load |
|---|---|---|
| Token mỗi turn | 100% (load full mọi lúc) | 25-60% tùy task |
| Attention focus | Bị dilute bởi info không liên quan | Tập trung vào file đã match rule |
| Maintain | 1 file dài, dễ thành 300+ dòng | 4 file ngắn, mỗi file một mục đích |
| Update frequency | Đổi 1 dòng, toàn file dirty | Chỉ file liên quan dirty |
| Debug "tại sao AI không biết X" | Đọc lại 300 dòng | Check rule load → file → nội dung |
| Onboarding cost | Cao (đọc cả 1 file dài) | Thấp (đọc identity trước) |
Lợi không phải lúc nào cũng đáng. Xem section sau.
Trade-off & pragmatic guidance
Khi nào nên tách:
- CLAUDE.md hiện tại > 200 dòng (Claude bắt đầu pattern-match thay vì đọc kỹ rule khi vượt ngưỡng này)
- Có nhiều task type khác biệt rõ rệt (code vs content vs research)
- Có > 1 user/role khác nhau dùng chung AI assistant
- Memory system đã có sẵn (ví dụ folder memory/ với index MEMORY.md) — pattern đã quen
Khi nào KHÔNG nên tách: - CLAUDE.md < 150 dòng và còn manage được — tách prematurely tốn công maintain - Chỉ làm 1 loại task (vd: dedicated code review bot) — không có gì để dynamic load - Single-user, single-project — overhead không xứng
Sai lầm thường gặp: - Tách rồi không viết loading rules → AI vẫn load full mọi session, thành tệ hơn (4 file thay vì 1, đọc 4 lần thay 1 lần) - Loading rules quá nhiều case → AI mất công match → load sai → output kém - Project.md không update → trở thành "memorial" của project cũ → AI lẫn lộn priorities
Quy tắc 200 dòng: giữ TỔNG context auto-load (root + always-load files) dưới 200 dòng. Vượt ngưỡng này, compliance của model với rule rớt mạnh — model bắt đầu pattern-match "có rule" thay vì thực sự đọc.
Kết luận
Prompt engineering là kỹ năng của 2024. Context engineering là kỹ năng của 2026 trở đi.
Khác biệt giữa người vẫn loanh quanh tweak từ ngữ và người đã build được AI system production-grade không phải prompt khéo hơn — mà là context được engineer đúng cách: structured, dynamic, đủ cho task, không thừa.
Cấu trúc 4 file + dynamic loading rules là một kiến trúc tối thiểu hoạt động được. Bạn không cần migrate ngay — nếu CLAUDE.md hiện tại < 150 dòng và đang work, đừng đập bỏ. Nhưng khi nó vượt 200 dòng và compliance bắt đầu kém, đây là refactor đáng làm.
Engineer the context. Design the architecture. Shape the environment.
Mỗi prompt sau đó sẽ cho output mà người chỉ tweak câu chữ không bao giờ replicate được.